簡稱 RNN,一種深度學習網路,專門設計處理序列資料,例如:文字、音訊、時間序列
自然語言處理 |
理解和生成人類語言 |
|---|---|
機器翻譯 |
將文字從一種語言翻譯成另一種語言 |
語音識別 |
將語音轉換為文字 |
機器學習 |
從序列資料中學習並做出預測 |
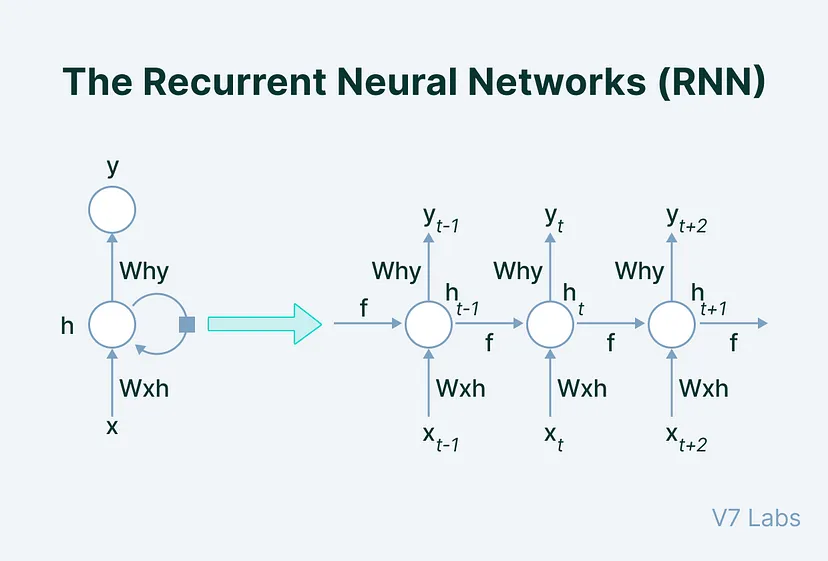
輸入層 |
接收序列資料 |
|---|---|
隱藏層 |
RNN核心包含狀態會隨著序列資料輸入而更新 |
輸出層 |
生成RNN預測 |
圖片來源:The Architecture of a Basic RNN
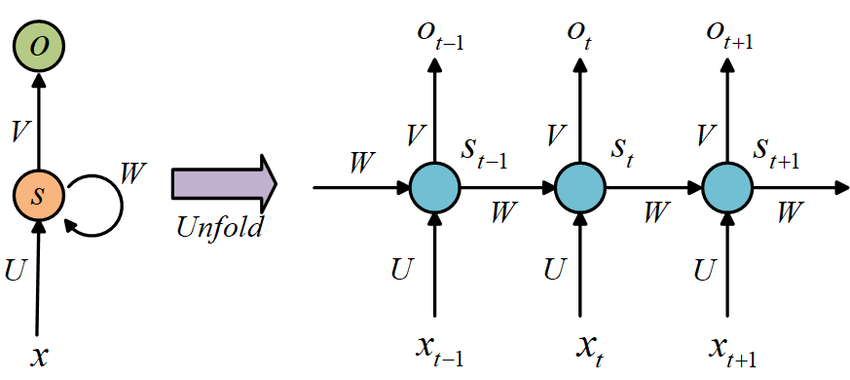
圖片來源:(https://www.researchgate.net/figure/Basic-RNN-structure_fig1_334464982)
One-to-OneOne-to-ManyMany-to-OneMany-to-Many(同步 many-to-many)Many-to-Many(非同步 many-to-many)這些是 RNN 在不同應用場景中的基本架構類型。每種類型都有不同的應用場景和技術挑戰,根據任務需求進行選擇
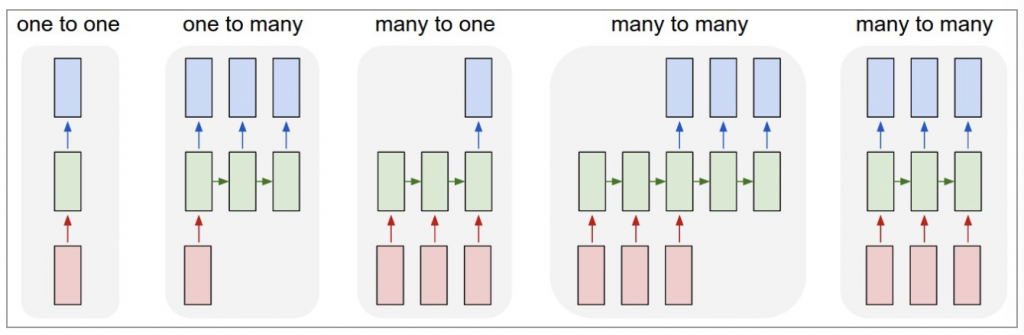
圖片來源:(https://www.cnblogs.com/wuliytTaotao/p/9512963.html)
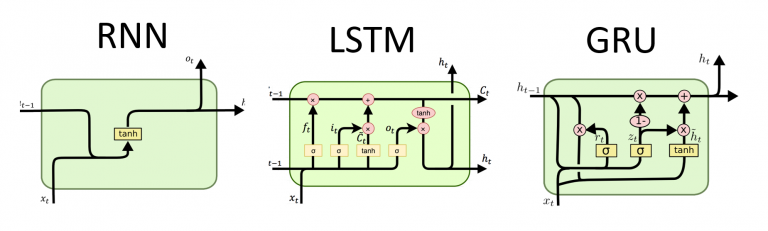
簡單遞歸神經網路(Simple Recurrent Neural Network, SRNN)最簡單RNN,只有一個隱藏層
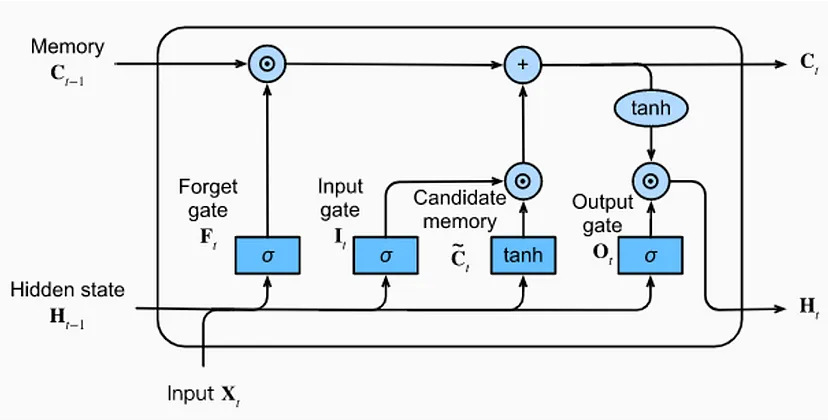
長短期記憶網路(Long Short-Term Memory, LSTM)是一種特殊RNN,專門設計處理長期依賴關係
圖片來源:An Intuitive Explanation of LSTM
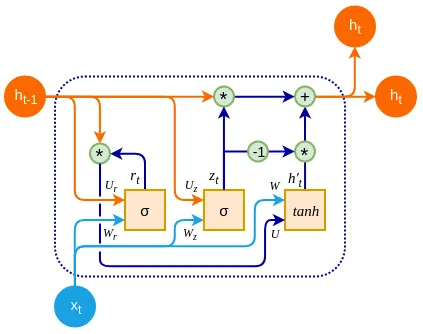
門控遞歸神經網路(Gated Recurrent Neural Network, GRU)是一種特殊RNN,專門設計處理短期依賴關係
圖片來源:Understanding Gated Recurrent Unit (GRU) in Deep Learning
圖片來源:(http://dprogrammer.org/rnn-lstm-gru)
| 優點 | 缺點 |
|---|---|
| 學習序列資料中時間依賴關係 | 訓練過程可能很耗時 |
| 處理大型資料集 | 需要大量的資料 |
| 各種序列處理任務中取得高精度 | 很難解釋模型的決策 |
h_t = f(W_xh_t-1 + U_x x_t + b) y_t = g(V_h h_t + b_y)
h_t |
第 t 時間步隱藏狀態 |
|---|---|
x_t |
第 t 時間步輸入 |
y_t |
第 t 時間步輸出 |
W_h |
隱藏狀態到隱藏狀態權重矩陣 |
U_x |
輸入到隱藏狀態權重矩陣 |
V_h |
隱藏狀態到輸出權重矩陣 |
b、b_y |
偏置向量 |
f、g |
非線性激活函數 |
工作原理第 t 時間步,RNN將前一時間步 隱藏狀態h_t-1 和當前時間步 輸入x_t 作為輸入,通過 權重矩陣W_h 和 U_x 進行加權求和,並加入 偏置向量b,然後,RNN 將加權求和後的結果通過 非線性激活函數f 進行處理,得到當前時間步 隱藏狀態h_t,最後,RNN 將當前時間步 隱藏狀態h_t 通過 權重矩陣V_h 進行加權求和,並加入 偏置向量b_y,通過 非線性激活函數g 進行處理,得到當前時間步 輸出y_t
雖然能夠記憶前一時間步的資訊,非常適合處理序列資料。但也會有 梯度消失 和 梯度爆炸 問題
梯度消失在RNN中,梯度會隨著時間步增加而逐漸消失。較早時間輸入,對時間步輸出影響較小。梯度消失問題會導致RNN難以學習長期依賴關係
梯度爆炸在RNN中,梯度也可能會隨著時間步的增加而逐漸爆炸。對較早時間步輸入,對時間步輸出影響較大。梯度爆炸問題會導致RNN訓練不穩定
為了解決梯度消失和梯度爆炸問題,提出許多方法,例如: 長短期記憶網路(LSTM) 和 門控循環單元(GRU)
長短期記憶網路(LSTM)LSTM結構中包含了三個門控機制:遺忘門、輸入門和輸出門。這三個門控機制可以幫助LSTM更好地控制梯度流,從而解決梯度消失和梯度爆炸問題
門控循環單元(GRU)GRU是一種與LSTM相似的RNN,結構中包含了兩個門控機制:重置門和更新門。GRU結構比LSTM更加簡單,但也能夠有效地解決梯度消失和梯度爆炸問題
import torch
import torch.nn as nn
import torch.optim as optim
# 超參數設定
input_size = 28
hidden_size = 100
num_classes = 10
num_layers = 2
sequence_length = 28
# 建構RNN模型
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_classes, num_layers):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
out, _ = self.rnn(x, h0)
out = out[:, -1, :]
out = self.fc(out)
return out
# 初始化模型、損失函數和優化器
model = RNN(input_size, hidden_size, num_classes, num_layers)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
資料來源:循环神经网络(Recurrent Neural Network,RNN)
什麼是 RNN (遞歸神經網路)?